SEM(構造方程式モデリング)の活用-中間特性を潜在変数化したモデルのご利益-<2016年12月19日>

共分散構造分析あるいは構造方程式モデリング(SEM:Structural Equation Modeling)と呼ばれる分析法が普及し始めたのは1990年代半ば以降とすると、もう約20年も経過していることになります。とはいえ、SEMの主要なユーザーは心理・社会・調査系であり、工業や品質の分野の適用例はさほど(前述の分野に比べれば)多くないようです。潜在変数という架空(フィクション?)の概念が品質分野にはなじみにくいという声も聞かれます。しかしながら、SEMの理論・方法論、あるいは統計的因果推論の考え方は、品質分野にも非常に役立つのではないかと思います。
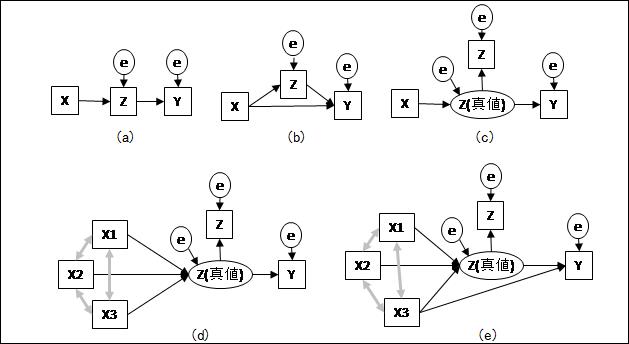
要因Xから反応Yへの影響が問題になっているとき、中間特性Zを間にはさんで、図(a)のような因果モデルを考える場合があります。
Xは制御や管理が可能な特性、Yは生産品の品質特性、Zは中間工程で計測可能な特性値などが該当すると思います。
十分なデータに対して上記因果モデルの適合がよければ、X→Yの影響をZが説明していることになります。「Xが上がるとZが上がるのでYが上がる」ということですね。そして、Zが一定であればXとYは無相関ということですから、YへのXの影響を管理するためにはZ以外の中間特性は不用である、という強い主張も可能です。
上記モデルの適合がよくない場合は、つまりXからYへの影響はZ経由で説明される間接影響だけでなく、X→Yの直接的なパスが必要ということです(図(b))。この直接パスの意味は、XからYへの影響のうち、Zで説明できない効果を表しています。Z以外の中間特性を探す必要があるのでしょうか。
ここで、中間特性Zに測定誤差が無視できない状況を考えてみます。仮にZの真値がX→Yの影響を完全に説明しているとすれば、因果モデルは図(c)になります。真の因果関係が図(c)の場合(Zの誤差分散が小さくない場合)に、図(a)のモデルをあてはめると適合が悪くなります。
(b)(c)はどちらも飽和モデルとして必ず解が求まるモデルです(適合度のよしあしを評価することはできません)。なので、(a)の適合が悪いとき、データだけからは(b)(c)のどちらの状況かはわからないのですが、Zの測定誤差がどの程度なのかがわかっていれば、いったん(c)をあてはめ、Zの誤差分散の推定値が先見情報と一致するかどうかで判断する、という作戦が考えられます。
また、Zが因果的影響を説明するとみられる要因Xあるいは反応Yが複数個あれば、飽和モデルではなくなり、適合度を評価できるモデルとなります。例えば、図(d)の適合がよければ、X1,X2,X3からYへの影響はZ(の真値)が完全に説明しているといえます。
図(d)の適合は悪いけれども図(e)の適合はよい、という場合は、X1,X2はZ経由でのみYに影響するけれども、X3だけはZ以外にもYを上げ下げするメカニズムが存在する、ということを意味しています。
固有技術による先見情報と照らし合わせつつ、SEMをレーダーのように使って、真の因果関係を探っていく作業は、有益な知見をもたらす可能性があります。また、その分析作業と思考プロセス自体が非常に面白いものです。

小島 隆矢 氏
(こじま たかや)
1990年東京大学工学部建築学科卒業
1997年東京大学大学院工学系研究科
建築学専攻博士課程修了 博士(工学)
東陶機器株式会社、
東京大学工学系研究科助手、
建設省建築研究所研究員、
独立行政法人建築研究所主任研究員を経て、2007年4月より早稲田大学人間科学部准教授
主な著書に「Excelで学ぶ共分散構造分析とグラフィカルモデリング」がある。





