SQC
セミナーレポート:「ビッグデータ時代のデータリテラシー1日コース」<2021年04月02日>
2021年2月26日(金)に東京・日科技連・東高円寺ビルで「ビッグデータ時代のデータリテラシー1日コース」を開催しました。
本コースは、2020年12月11日にオンライン無料講演会で紹介された「新しいデータリテラシーの基礎を学ぶ ~個のデータから系を知る~」の内容について、“R”を用いて実際に手を動かしながら学習することができる講座です。
多数のご参加を賜りました本セミナーに、
品質管理セミナーベーシックコース講師の南 賢治氏が聴講されました。
ご寄稿いただきました受講レポートを公開させていただきます。
本コースは、2020年12月11日にオンライン無料講演会で紹介された「新しいデータリテラシーの基礎を学ぶ ~個のデータから系を知る~」の内容について、“R”を用いて実際に手を動かしながら学習することができる講座です。
多数のご参加を賜りました本セミナーに、
品質管理セミナーベーシックコース講師の南 賢治氏が聴講されました。
ご寄稿いただきました受講レポートを公開させていただきます。
1.参加動機
私はデータに基づく品質改善や品質管理全般の業務を担当しており、昨年12月に開催された吉野先生の無料オンライン講演会「新しいデータリテラシーの基礎を学ぶ ~個のデータから系を知る~」を受講させて頂いた際に共感することが多く、更に2月の本コースではより詳細をご紹介されるとのことでしたのでとても興味がありました。
日頃から、データに基づく品質改善を行う際に、取り組む問題や扱うデータの背景について関係者と確認し合うと、「そもそも問題の本質は別のところにありそうですね」とか、「測定の信頼性が低く且つロットの代表とは言えるか不明なサンプリングによって得られた過去のデータでは、統計的な分析しても真の現状把握とはなりそうにありませんね」等々、問題やデータの背景を把握することの重要性について痛感していました。
本コースではビッグデータ時代だからこそ注意すべきデータリテラシーについて、吉野先生より詳しくご紹介頂けるとのことでしたので、是非とも自社の取組みに活かしたいと考え受講させていただきました。
2.セミナー参加を通して
冒頭、演習で使う“R”のインストールからコースが始まりました。リモート講義ということもあるのでしょうが、受講者によって会社のPC環境などで上手く“R”のインストールができない方にもチャット機能を使ってインストール時の悩み事を確認し、とても親切に指導していただきました。最終的に“R”のインストールができなかった受講者に対しても吉野先生の画面を通して“R”を使った演習の様子が分かるよう講義が工夫されていました。
日科技連での集合研修であれば、予め用意されたPCを使うことで全く問題なく演習もできるのでしょうが、リモート研修ということもあり、冒頭から吉野先生の受講者への配慮や思いやりが感じられる講義でした。
また、演習に使う“R”のスクリプトも吉野先生が作成されてものを事前に各自に配布していただいており、初めて“R”を使う人でもスムーズに演習が行えるように工夫されていました。
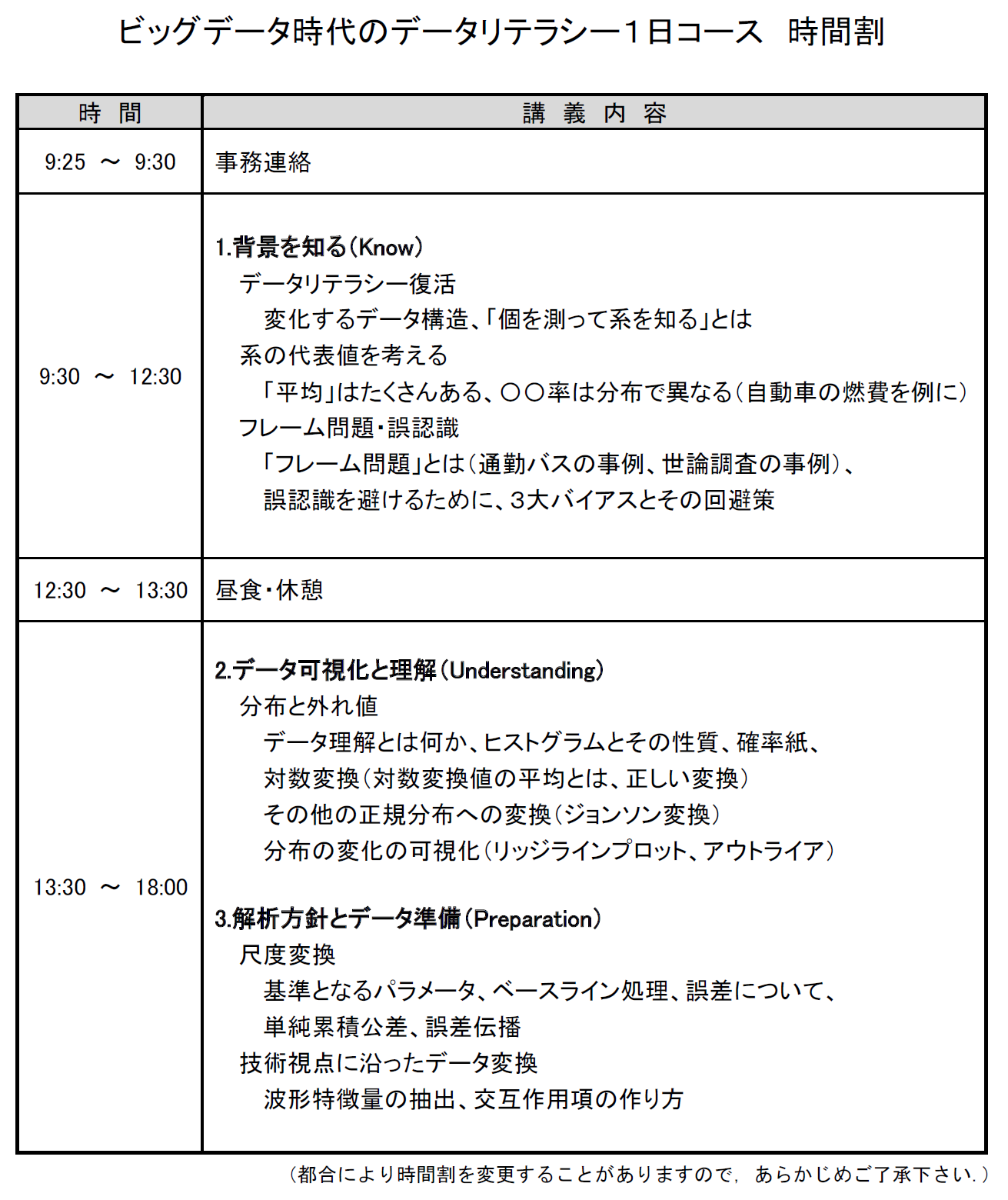
3章に分かれた1日コースの中で、午前中にじっくりと第1章の「背景を知る(Know)」について説明いただき、午後には第2章「データ可視化と理解(Understanding)」と第3章「解析方針とデータ準備(Preparation)」について説明いただきました。
特に第1章の「背景を知る(Know)」では、本コースの主題でもあるビッグデータ時代のデータリテラシーを理解することが、如何に重要で必要なことであることかを事例と共に分かり易く説明いただきました。
後半の第2,3章では、高度な手法の紹介もあり、私も含めて受講者によっては半日では十分な理解には至らない点も多く感じましたが、様々な手法の特徴について知ることができたことは1日を通して非常に有用な講義であると感じました。
3.コース内容の詳細
時間割
<講義:第1章 背景を知る(Know)>
- ・データ解析の前に知っておくべき事として、「何を対象にして調査したデータか?」、「それは生データか特徴量(加工データ)か?」について色々な角度から説明いただきました。
- データを扱う技術者の心構えはじめ、「フレーム問題」と言われるデータの背景についての理解すべきことについて説明いただきました。
- ・「個を測って系を知る」ことの例として、店でのビールとおむつの売り上げに関して従来は時系列として「系を観測」したいたのに対して、今後はお客様ごとの「個を観測」するといった「価値視点の変化」から「観測視点の変化」へシフトすることの重要性について改めて再認識することができました。
- 特徴量の中でも平均値などの代表値や相関係数などについて、様々な算出のしかたがあることを説明いただきました。
- ・“R”を用いた小学校のクラス平均身長などの分かりやすい事例を用いたこれまで体験したことのない演習もあり、とても興味深く学ばせていただきました。
- ・幾何平均、調和平均や重み付き平均など対象に合った平均について説明いただきました。
- ・燃料消費率を題材にして、誤差分布のモデルが異なると傾きの値が異なることを説明いただきました。
- ・バスの混み具合を題材にして、会社側と組合側との言い分の違いと「稼働率」という一致する指標が存在することを説明いただきました。
- ・更にフレーム問題の事例として、春闘時の企業調査と世論調査についてのフレームの読み解き方について説明いただき、特にビッグデータ時代には、データ生成の背景を知り、解析に正しくつなげる努力が常に必要であることを改めて再認識することができました。
- ・データ理解とは単なる「系の可視化」ではないこと、またデータクリーニングでは機械に頼り切りにしてはいけないことを再認識させられました。
- ・分布形状を知る際には種々の確率紙を用いることが重要であり、適用する分布の使い分けについて説明いただきました。
- 系(集団)の性質を知って、解析上の弊害が無いように写像(変数変換)を行うことの重要性について説明いただきました。
- ・データの可視化や変数変換時の留意点として、分布形を見るときには確率紙を使うことを推奨されていて、日頃の可視化の仕方に過ちがなかったことも確認できましたが、一方で安易な対数変換はさけるべきとのことでしたので、今後しっかりと意識していきたいと思います。
- ・分布の変化や時系列性の可視化としてウォーターフォールプロット、リッジラインプロットおよびランダムウォークsin関数に誤差を乗せたグラフ化について説明いただきました。
- ・変数間の関連性とその可視化として、ヒートマップやグラフィカルモデルについて説明いただきました。
- ・データを理解するためには、対数や時系列性の可視化などで、行間がゆがんでいないかに注意を払う必要があること、更に列間の相関や共起性については前もって知っておかなければいけないことを学ぶことができました。
- ・また、“R”を用いたポリコリック相関やバブルチャートなど、これまで体験したことのない演習もあり、とても興味深く学ばせていただきました。
- ・解析方針について、先ずは全体のプロトコルを立案することが最初の一歩とのことで、「課題の把握」に始まり、「データの理解」→「データ加工」→「モデル作成」→「評価」→「展開/共有」へと全体の流れの中で、今回のコースの位置づけを明確に説明いただきました。
- ・特に「データの理解」における「生データの収集」以降に必要なアクション、更に「データ加工」において、先ず「特徴量の設計」から始まることの重要性について説明いただきました。
- 特に、インプットデータの重要性として挙げられていた「ゴミを突っ込んだらゴミしか出てこない(GIGO)」など、日頃の品質改善でデータを扱う際にも共感できる解析のいろはも再認識することができました。
- ・また、データクリーニングが恣意的な操作であることから意図せぬ改竄・捏造・隠ぺいが入りやすいため周囲すべきであることと同時に元データをきちんと残しておくことの重要性について説明いただきました。
- ・データ準備として、解析目的にあった行や列を用意しなければならいことを学ばせていただきました。
- ・必要な行(サンプル)がない場合には、不均衡データの補正のためのスモートの有用性を説明いただきました。
- ・また必要な列(変数)がない場合には、特徴量などの追加の必要性について説明いただきました。
- 時間の関係もあり、当初予定されていた“R”の演習の全ては時間内に終えられませんでしたが、演習の全スクリプトは配信されており、また、テキストも追って配信して頂けましたので、今後の復習にとても助かりました。
<最後に>
本コースに聴講させていただきとても多くのことを学ばせていただき誠にありがとうございました。データ量の大小に限らず、統計ソフトにインプットすればある程度の知識があれば様々な可視化が容易にできるようになった昨今、そもそもインプットしようとするデータの背景にあるフレームまできちんと把握していなければ、求められる考察が大きく異なってしまうことを再認識することができました。
今回配布いただいた講義資料は、吉野先生のご厚意により、本コースで得た資料であることを明記した上で社内研修資料としても活用させていただけるとのことでしたので、一人でも多くの人がデータリテラシーの理解不足による過ちを減らせるように活かさせていただきたいと思います。また、更に理解を深めて貰うためにも吉野先生から直接ご指導いただける本コースを社内関係者に是非紹介したいと思います。
今日のビッグデータ時代の中で、データリテラシーについてモヤモヤするような問題意識をお持ちの方々には、吉野先生に直接ご指導いただける本コースはとてもお奨めです。

南 賢治(みなみ けんじ)氏
略歴
1963年生まれ。1987年芝浦工業大学工学部卒業。同年日本発条株式会社入社。
技術本部 品質管理部 主査
主な担当業務
・データに基づく品質改善活動の推進
・品質管理に関する社員研修計画作成、教育実施
・自工程完結に基づくテーマ活動の推進
一般財団法人 日本科学技術連盟 品質管理セミナーベーシックコース東京幹事、講師
これならできる!慢性不良撲滅法 品質改善シナリオ“サザンフロー”の活用(共著:日科技連出版社)






〈お問い合わせ先〉一般財団法人 日本科学技術連盟 品質経営研修センター 研修運営グループ
〒166-0003 東京都杉並区高円寺南1-2-1 / TEL:03-5378-1213
Copyright © 2021 Union of Japanese Scientists and Engineers. All rights Reserved.